Generalizable 3D part segmentation is important but challenging in vision and robotics. Training deep models via conventional supervised methods requires large-scale 3D datasets with fine-grained part annotations, which are costly to collect. This paper explores an alternative way for low-shot part segmentation of 3D point clouds by leveraging a pretrained image-language model, GLIP, which achieves superior performance on open-vocabulary 2D detection. We transfer the rich knowledge from 2D to 3D through GLIP-based part detection on point cloud rendering and a novel 2D-to-3D label lifting algorithm. We also utilize multi-view 3D priors and few-shot prompt tuning to boost performance significantly. Extensive evaluation on PartNet and PartNet-Mobility datasets shows that our method enables excellent zero-shot 3D part segmentation. Our few-shot version not only outperforms existing few-shot approaches by a large margin but also achieves highly competitive results compared to the fully supervised counterpart. Furthermore, we demonstrate that our method can be directly applied to iPhone-scanned point clouds without significant domain gaps.
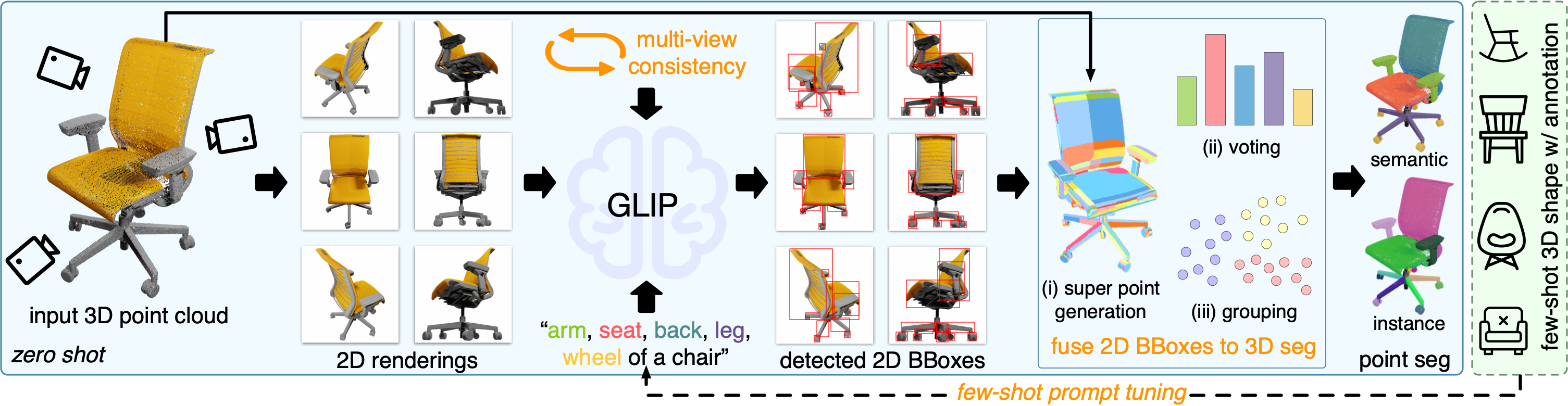
The proposed components are highlighted in orange.
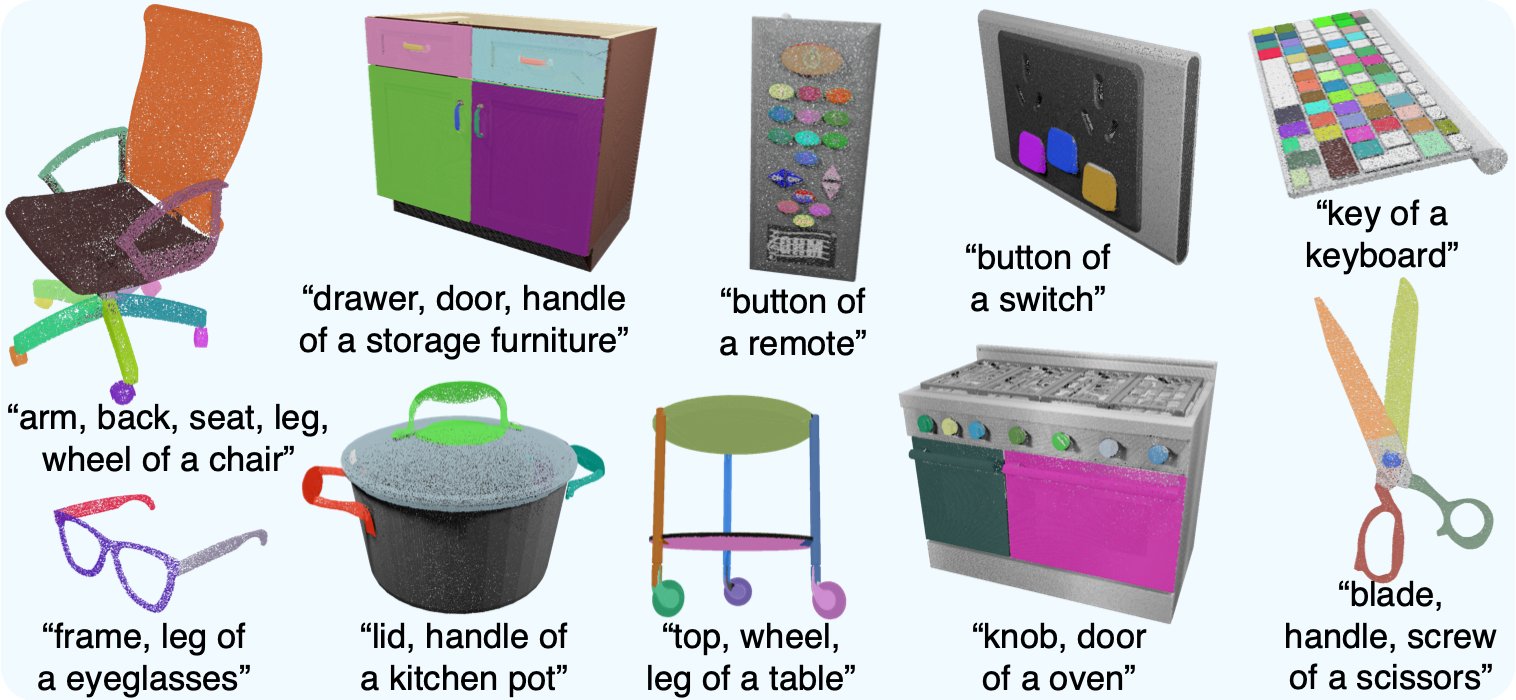
PartSLIP (8-shot) results on the PartNet-Ensembled dataset. Different part instances are in different colors.

PartSLIP can be directly applied to real-world point clouds without encountering significant domain gap: iPhone-scanned point clouds (first row), text prompts (second row), and PartSLIP (8-shot) results (third row).
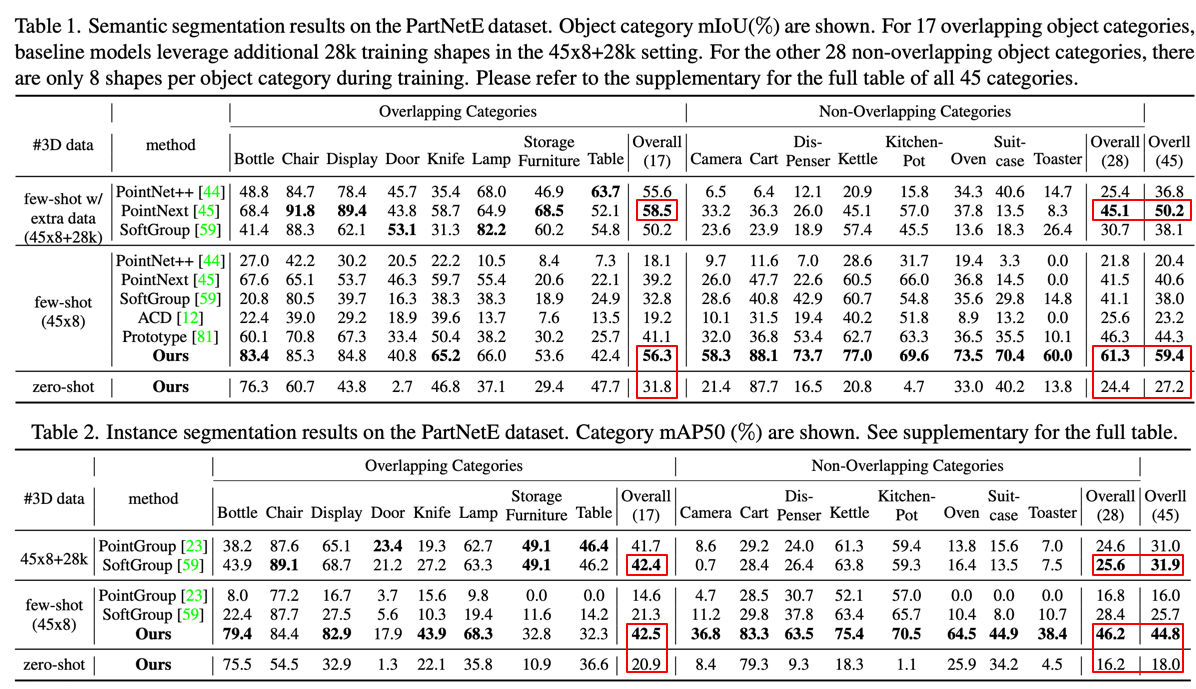
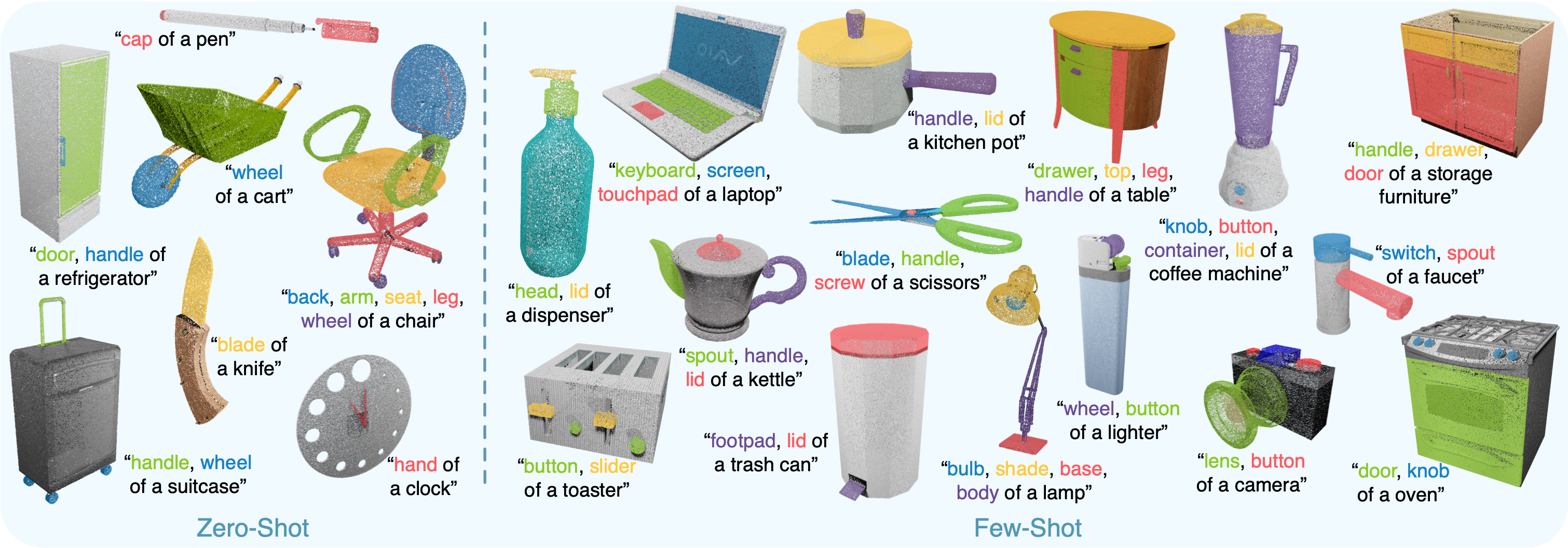
PartSLIP achieves impressive zero-shot performances, and few-shot results are highly competitive compared to the fully supervised counterparts.
@inproceedings{liu2023partslip,
title={Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models},
author={Liu, Minghua and Zhu, Yinhao and Cai, Hong and Han, Shizhong and Ling, Zhan and Porikli, Fatih and Su, Hao},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21736--21746},
year={2023}
}